
比英伟达工程师还熟练!DeepSeek R1+测试时Scaling自动优化GPU内核
比英伟达工程师还熟练!DeepSeek R1+测试时Scaling自动优化GPU内核英伟达巧妙地将DeepSeek-R1与推理时扩展相结合,构建了全新工作流程,自动优化生成GPU内核,取得了令人瞩目的成果。
来自主题: AI技术研报
8333 点击 2025-02-15 16:27
 搜索
搜索
英伟达巧妙地将DeepSeek-R1与推理时扩展相结合,构建了全新工作流程,自动优化生成GPU内核,取得了令人瞩目的成果。
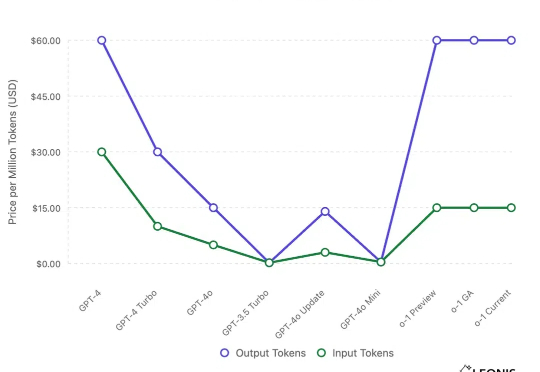
自一月以来, DeepSeek 在 AI 领域引发了极大的热度,也出现了大量分析文章。其中来自 Leonis Capital 于 2.6 发表于 Substack 上的文章:「DeepSeek: A Technical and Strategic Analysis for VCs and Startups」

最新大语言模型推理测试引众议,DeepSeek R1常常在提供错误答案前就“我放弃”了?? Cursor刚刚参与了一项研究,他们基于NPR周日谜题挑战(The Sunday Puzzle),构建了一个包含近600个问题新基准测试。
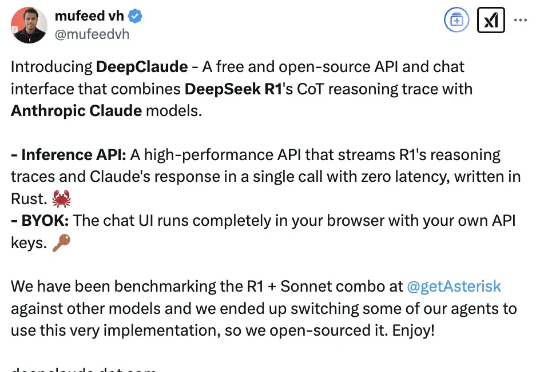
让DeepSeek代替Claude思考,缝合怪玩法火了。原因无它:比单独使用DeepSeek R1、Claude Sonnet 3.5、OpenAI o1模型的效果更好。DeepClaude应用本身100%免费且开源,在GitHub上已揽获3k星星(当然API要用自己的)。

这项尝试只用到了 R1 模型和基本验证器,没有针对 R1 的工具,没有对专有的英伟达代码进行微调。其实根据 DeepSeek 介绍,R1 的编码能力不算顶尖。

【新智元导读】仅凭测试时Scaling,1B模型竟完胜405B!多机构联手巧妙应用计算最优TTS策略,不仅0.5B模型在数学任务上碾压GPT-4o,7B模型更是力压o1、DeepSeek R1这样的顶尖选手。

这应该是我知道的第一家有自己大模型的大厂,第一次在面向C端的AI助手应用中,第一次接入DeepSeek R1。这个意义影响还是非常深远的,腾讯在AI这一步上,好像走的格外的开放,从之前的批量开源MoE、混元绘图模型、混元视频模型、混元3D模型,还有今天这神之一手接入DeepSeek R1。
整个春节假期,我眼睁睁看着 DeepSeek 从“全民狂欢”变成“全民卡顿”——官网十问九崩,还有谁没被“服务器正忙,请稍后重试”的提示,搞崩溃过。
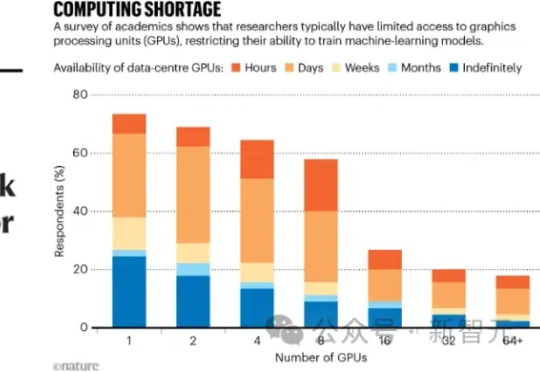
梁文峰说,钱从来都不是问题,唯一担心的是缺算力。不过,基于国产昇腾算力的DeepSeek R1系列推理API,性能已经直接对标高端GPU了!而且,华为已经率先携手国内15所头部高校,打造出了独一份的科教创新卓越/孵化中心,通过产教融合、科教融汇破解高校科研的算力困局。
用了两天接入了DeepSeek R1的飞书,坦率的讲,我已经被彻底折服了,今天,我必须要写一篇文章安利一下。故事是这样的。飞书的多维表格,在前天下午接入了满血版的DeepSeek R1。